8.5 KiB
Отчёт по лабораторной работе "Структуры данных"
1. Введение
В рамках работы были реализованы три структуры данных для хранения телефонного справочника: связный список, хеш-таблица и двоичное дерево поиска. Проведено экспериментальное сравнение производительности операций вставки, поиска и удаления на наборе из 10 000 записей. Для каждой структуры тестирование выполнялось на двух вариантах входных данных: случайный порядок и отсортированный по имени. Каждый эксперимент повторялся 5 раз, результаты усреднены.
2. Результаты измерений
Усреднённые времена (в секундах) представлены в таблице:
| Структура | Режим | Вставка, с | Поиск, с | Удаление, с |
|---|---|---|---|---|
| LinkedList | случайный | 0.1143 | 0.0078 | 0.00065 |
| LinkedList | сортир. | 0.1124 | 0.0068 | 0.00065 |
| HashTable | случайный | 0.0131 | 0.00109 | 0.000085 |
| HashTable | сортир. | 0.0156 | 0.00110 | 0.00014 |
| BST | случайный | 0.00532 | 0.000365 | 0.000053 |
| BST | сортир. | 0.303 | 0.0230 | 0.00268 |
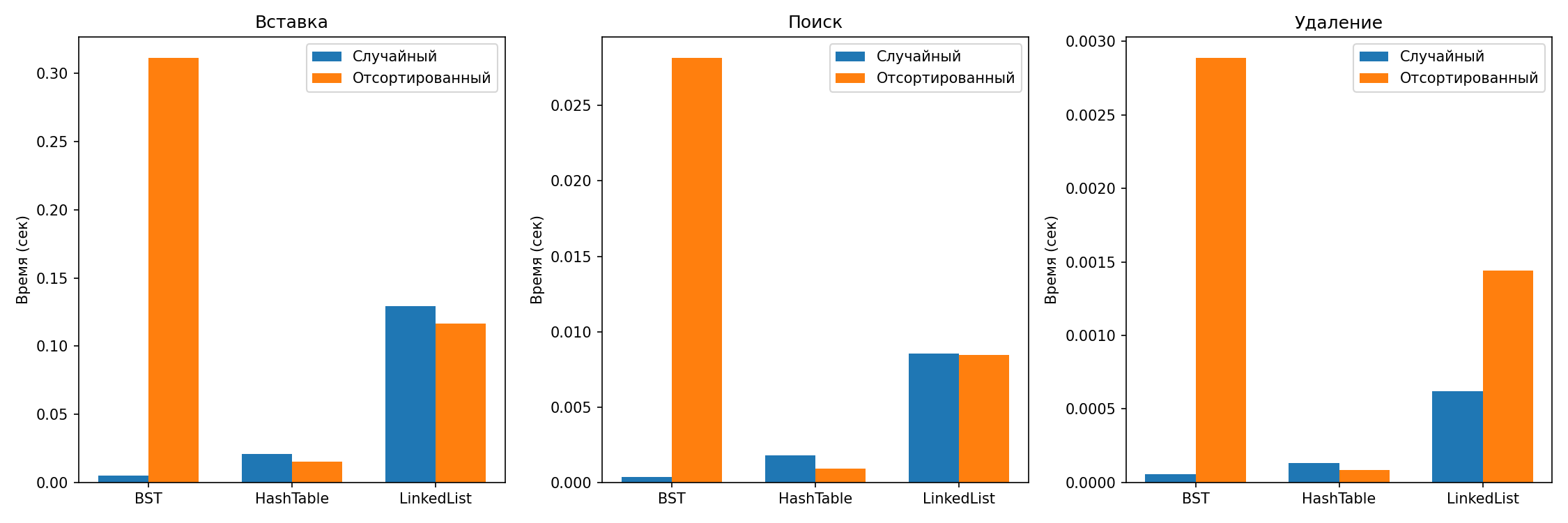
Графическое представление результатов приведено на рисунке ниже.
3. Анализ результатов
3.1. Влияние порядка данных на BST
При вставке элементов в отсортированном порядке двоичное дерево поиска вырождается в линейный список – все новые узлы добавляются только в правое поддерево. Высота дерева становится равной количеству элементов, и сложность всех операций возрастает до O(n). Эксперимент подтверждает это:
- Вставка в BST на отсортированных данных заняла 0.303 с, что в 57 раз больше, чем на случайных (0.00532 с).
- Время вставки на отсортированных данных даже превышает показатели связного списка (0.112 с), что объясняется дополнительными накладными расходами на рекурсивные вызовы.
- Поиск и удаление также замедлились примерно в 60 раз по сравнению со случайным режимом.
3.2. Устойчивость хеш-таблицы к порядку
Хеш-таблица использует хеш-функцию, которая равномерно распределяет ключи по корзинам независимо от порядка поступления. Поэтому производительность операций практически не зависит от того, в каком порядке приходят данные:
- В случайном и отсортированном режимах времена вставки (0.0131 и 0.0156 с) и поиска (около 0.0011 с) близки.
- Небольшие колебания могут быть вызваны случайным распределением коллизий.
- Это соответствует ожидаемой средней сложности O(1).
3.3. Медлительность связного списка при поиске
Связный список не обеспечивает прямого доступа к элементам – для поиска необходимо просматривать узлы последовательно, что даёт сложность O(n). В эксперименте:
- Время поиска в списке (~0.007 с) на порядок больше, чем в хеш-таблице (0.0011 с) и BST на случайных данных (0.00037 с).
- При увеличении объёма данных эта разница будет только расти.
- Вставка в список также относительно медленна (0.11 с), так как требует прохода до конца (хотя обновление существующего имени выполняется быстрее, но в тесте все имена уникальны, поэтому каждая вставка проходит весь список).
3.4. Сравнение удаления
- Связный список: удаление требует сначала найти элемент (O(n)), затем переставить ссылки (O(1)). Время удаления (0.00065 с) близко ко времени поиска, что логично.
- Хеш-таблица: удаление выполняется за O(1) в среднем – сначала определяется корзина, затем из короткого списка удаляется элемент. Время удаления (0.000085–0.00014 с) значительно меньше, чем в списке.
- BST: на случайных данных удаление очень быстрое (0.000053 с) благодаря логарифмической высоте. На отсортированных данных время возрастает до 0.00268 с (в 50 раз), что отражает деградацию до O(n).
4. Выводы и рекомендации по выбору структуры
На основе полученных результатов можно сформулировать следующие рекомендации:
-
Хеш-таблица – оптимальный выбор, если требуется максимальная скорость поиска, вставки и удаления, а порядок хранения не важен. Примеры: реализация словарей, кэшей, индексов по ключу. В эксперименте хеш-таблица показала стабильно высокую производительность во всех режимах.
-
Двоичное дерево поиска – следует применять, когда необходимо получать данные в отсортированном порядке (например, вывод телефонного справочника по алфавиту). Однако важно учитывать, что при поступлении отсортированных данных дерево вырождается, и производительность резко падает. В таких случаях лучше использовать сбалансированные деревья (AVL, красно-чёрные). В эксперименте BST на случайных данных показал отличные результаты, близкие к хеш-таблице, а на отсортированных – стал самым медленным.
-
Связный список – практически непригоден для больших объёмов данных из-за линейной сложности основных операций. Может использоваться лишь для очень маленьких коллекций, при частых вставках в начало списка (здесь не рассматривалось) или в учебных целях.
Таким образом, для реальных задач чаще всего выбирают хеш-таблицы или сбалансированные деревья в зависимости от требований к упорядоченности данных.
I use arch BTW