4.5 KiB
Отчет по лабораторной работе "Структуры данных"
1. Введение
В ходе выполнения лабораторной работы были выполнены реализации трех структур для хранения и обработки данных телефонных номеров:
- Связный список
- Хеш-таблица
- Двоичное дерево поиска.
Практическая часть включала в себя такие операции как: добавление или обновление телефонного номера, удаление телефонного номера, поиск владельца телефонного номера и составление списка из кортежей вида (владелец, номер). Каждое выполнение функций проводилось с списоком из кортежей вида (владелецб номер), в котором было 1000 уникальных имен и еще 9000 имен, которые уже были использованны (всего 10000 кортежей). Каждое тестирование структур выполнялось для сортированного и не сортированного начального списка 10 раз.
2. Результаты измерений
Данные в таблице отражают среднее время в милисекундах выполнения структур.
| Структура | Начальный список | insert, мс | find, мс | delete, мс | create list, мс |
|---|---|---|---|---|---|
| LinkedList | not sorted | 165.61 | 1.767 | 3.418 | 31.795 |
| LinkedList | sorted | 171.01 | 1.720 | 3.440 | 21.378 |
| HashTable | not sorted | 17.15 | 0.278 | 0.320 | 48.080 |
| HashTable | sorted | 17.49 | 0.284 | 0.321 | 47.911 |
| BST | not sorted | 52.95 | 0.772 | 0.660 | 0.283 |
| BST | sorted | 162.70 | 1.809 | 1.564 | 1.626 |
Изходя из полученных значений можно построить столбчатую диаграмму:
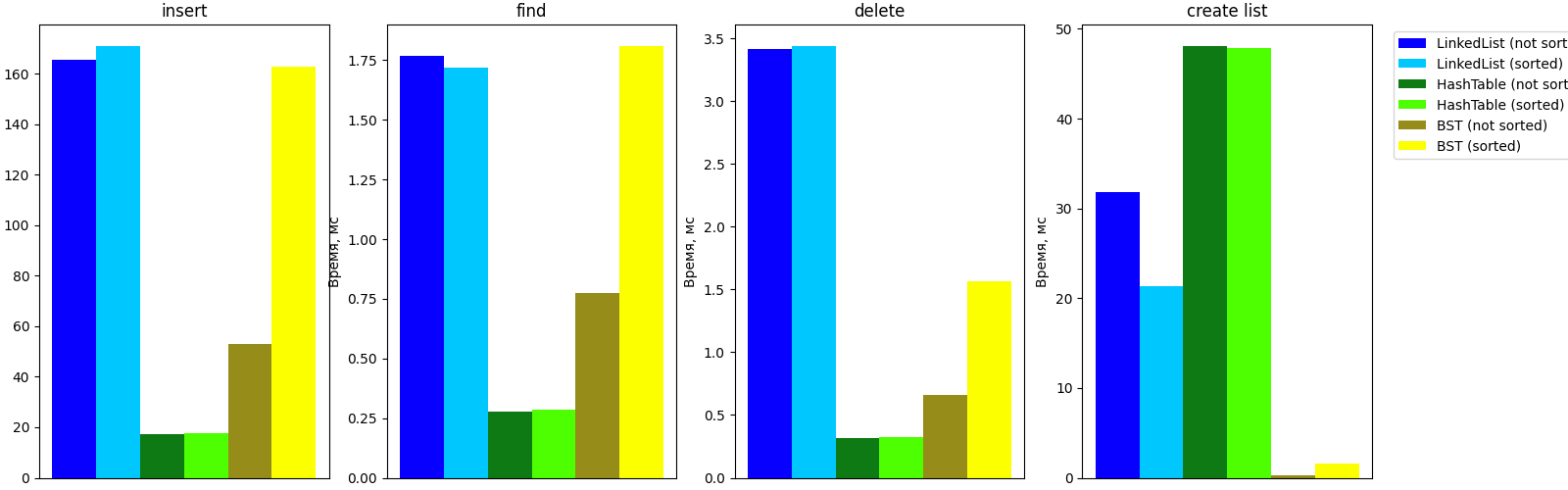
3. Анализ полученных данных
3.1 Зависимость скорости работы BST от порядка ввода данных.
Из полученных данных можно заметить, что для BST порядок ввода сильно сказывается на результате скорости выполнения программы: при послутплении неотсортированных данных программа справляется примерно в 3 раза быстрее. Связано это с тем, что каждое новое значение, при сортированных данных, будет больше предыдущего, а соответственно будет каждый раз создаватся правый лист, из-за чего высота дерева становится равной количесвту всех уникальных имен, вседствии чего сложность возрастает до О(n), а двоичное дерево превращается в своебразный связный список. Даже если сравнивать связный список и такое дерево, то скорость запонения с помощью такого способа проигрывает даже связному списку. Связано это с тем, что, хоть дерево здесь и будет выполнять роль связного списка, оно всеравно будет в каждом узле создавать новый левый лист со значением None, что замедляет его работу.
3.2 Независимость скорости выполнения заполнения хеш-таблицы от порядка вводных данных
Из эксперемента можно заметить, что скорость заполнения хеш-таблицы сортированными и несортированными данными почти одинакова(разница менее 2%). Это объясняется наличием бакетов, которые распределяют данные.