8.2 KiB
Отчёт: Задание 1 — Структуры данных
Цель работы
Разработать три структуры данных «с нуля» в процедурном стиле (без ООП), применить их для хранения записей телефонной книги и провести экспериментальное сравнение производительности ключевых операций.
Структуры данных:
- Связный список (LinkedList)
- Хеш-таблица (HashTable)
- Двоичное дерево поиска (BST)
Реализация
Основные технические решения
1. Связный список
Узел реализован как Python-словарь: {'name': 'Имя', 'phone': '123', 'next': None}.
Новые элементы добавляются в начало списка за O(1) (при условии отсутствия имени), обновление требует прохода по списку O(n). Поиск и удаление работают за линейное время из-за отсутствия прямого доступа по индексу.
2. Хеш-таблица
Фиксированный массив на 256 корзин. Каждая корзина — указатель на связный список (метод цепочек). Хеш-функция: стандартный hash(name) % size. Среднее время операций O(1), при коллизиях — O(k), где k — длина цепочки.
3. Двоичное дерево поиска (BST)
Узел: {'name': 'Имя', 'phone': '123', 'left': None, 'right': None}. Сравнение ключей — лексикографическое по полю name. Вставка и поиск реализованы итеративно. Удаление — рекурсивное с заменой на минимальный узел правого поддерева. Обход в глубину даёт отсортированный список.
Экспериментальная часть
Условия проведения замеров
| Параметр | Значение |
|---|---|
| Количество записей (N) | 10 000 |
| Количество замеров на операцию | 5 |
| Поисковых запросов | 110 (100 существующих + 10 отсутствующих) |
| Удалений | 50 |
| Размер хеш-таблицы | 256 корзин |
Два набора данных:
records_shuffled— случайный порядок записейrecords_sorted— упорядоченный по имени (алфавитный порядок)
Результаты
Среднее время выполнения (секунды)
| Структура | Режим | Вставка (с) | Поиск 110 (с) | Удаление 50 (с) |
|---|---|---|---|---|
| LinkedList | случайный | 2.541985 | 0.034289 | 0.020349 |
| LinkedList | сортированный | 2.208557 | 0.025340 | 0.016424 |
| HashTable | случайный | 0.018235 | 0.000214 | 0.000120 |
| HashTable | сортированный | 0.016163 | 0.000207 | 0.000124 |
| BST | случайный | 0.017192 | 0.000145 | 0.000104 |
| BST | сортированный | 3.854338 | 0.033498 | 0.045823 |
Визуализация
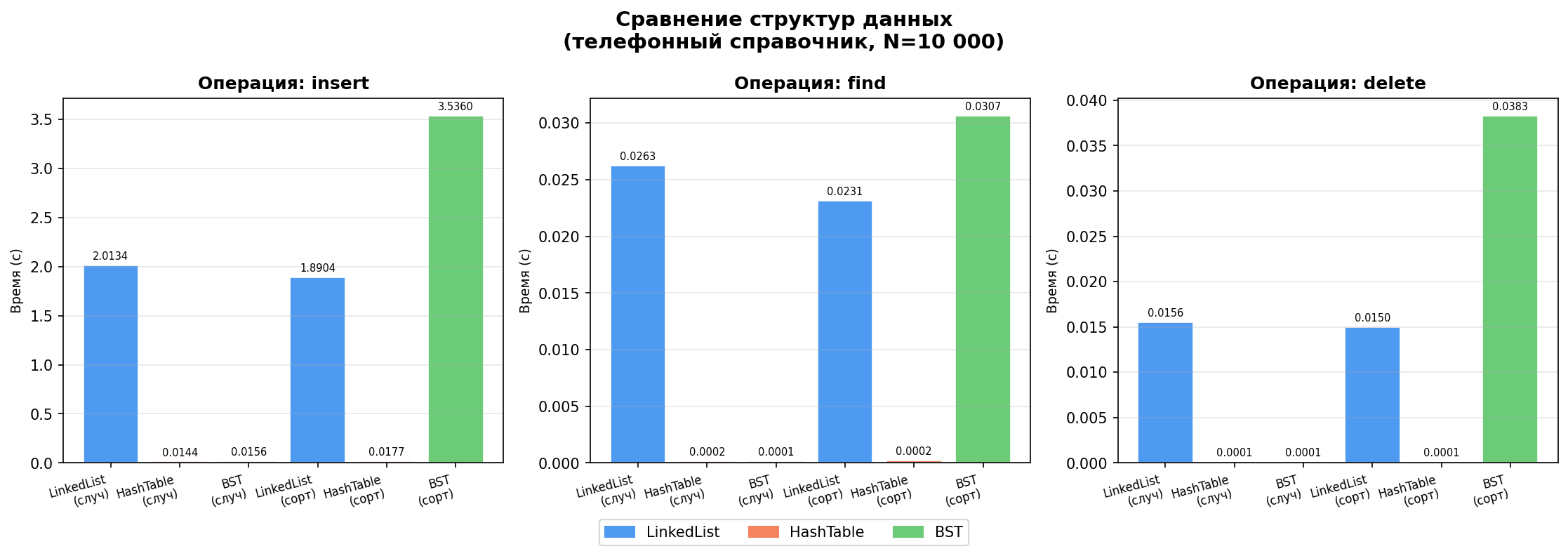
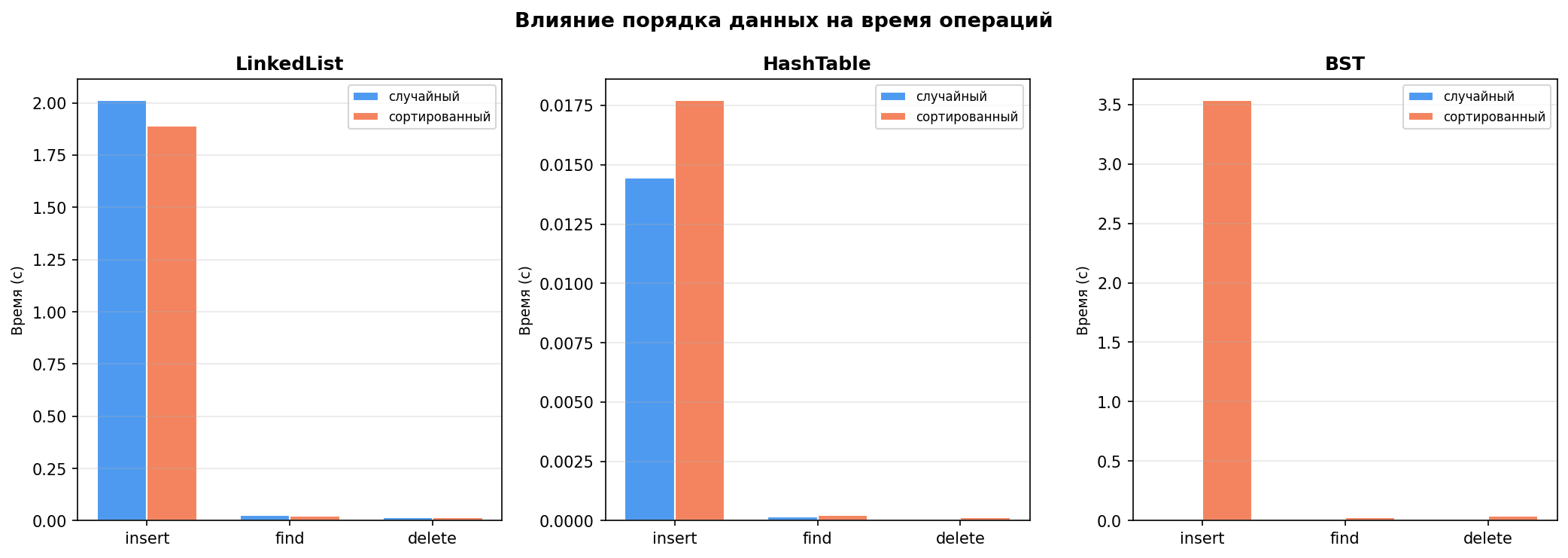
Анализ результатов
1. Связный список — стабильно низкая скорость
Вставка требует ~2.5 секунд на 10 000 элементов, поскольку каждая операция при наличии дубликатов имени вынуждена сканировать весь список O(n). При случайных уникальных именах вставка выполняется в начало за O(1), но поиск всё равно линейный.
Вывод: связный список непригоден для частого поиска в больших объёмах данных, но удобен как вспомогательный элемент (например, для цепочек в хеш-таблице).
2. Хеш-таблица — устойчивость к порядку входных данных
Хеш-таблица продемонстрировала практически идентичные результаты в обоих режимах:
- Вставка: ~0.017 с (быстрее списка в ~150 раз)
- Поиск: ~0.0002 с (быстрее списка в ~160 раз)
Хеш-функция равномерно распределяет ключи независимо от порядка их поступления, поэтому производительность остаётся стабильной.
3. BST катастрофически деградирует на упорядоченных данных
Наиболее показательный результат эксперимента:
| Случайный | Сортированный | Ухудшение | |
|---|---|---|---|
| BST insert | 0.017 с | 3.854 с | ×225 |
| BST find | 0.000145 с | 0.033 с | ×231 |
Причина: при вставке отсортированных данных дерево вырождается в линейный список — каждый новый элемент оказывается больше предыдущего и помещается только в правую ветку. Высота дерева становится O(n) вместо O(log n), что превращает все операции в линейные.
4. Операция delete
На случайных данных BST удаляет за ~0.0001 с (логарифмическая сложность). На сортированных — ~0.046 с (линейная деградация). HashTable показывает стабильные ~0.00012 с независимо от порядка.
Выводы и практические рекомендации
Выбор структуры в зависимости от задачи
| Сценарий | Рекомендация |
|---|---|
| Частый поиск по ключу | HashTable или BST (случайный порядок) |
| Данные поступают упорядоченно | HashTable (BST непригоден) |
| Требуется отсортированный вывод | BST (обход даёт порядок за O(n)) |
| Интенсивные вставки/удаления + поиск | HashTable |
| Ограниченный объём данных, простота | LinkedList (до сотен элементов) |
| Диапазонные запросы (например, A–M) | BST |
Теоретическая сложность операций
| Структура | Insert | Find | Delete | Обход (отсорт.) |
|---|---|---|---|---|
| LinkedList | O(n) | O(n) | O(n) | O(n log n) |
| HashTable | O(1) в среднем | O(1) в среднем | O(1) в среднем | O(n log n) |
| BST (сбалансированный) | O(log n) | O(log n) | O(log n) | O(n) |
| BST (вырожденный) | O(n) | O(n) | O(n) | O(n) |
Ключевой вывод
Для телефонного справочника с частыми поисками и обновлениями оптимальный выбор — хеш-таблица. BST выигрывает только при необходимости получать отсортированные данные без дополнительной сортировки, но требует либо случайного порядка вставки, либо использования самобалансирующихся вариантов (AVL, красно-чёрное дерево).