4.7 KiB
Отчёт по лабе: телефонный справочник на трёх структурах
Что делал
Реализовал три структуры для хранения записей (имя – телефон) без классов, только словари и ссылки:
-
Связный список – каждый узел
{'name': ..., 'phone': ..., 'next': ...}.
Вставка в начало, перед этим проверка на дубликат (поиск по всему списку). -
Хеш-таблица – 13 корзин, в каждой связный список. Хеш-функция: сумма кодов символов
% 13.
Вставка/поиск/удаление – через хеш + вызов функций списка для конкретной корзины. -
Двоичное дерево поиска – узел
{'name': ..., 'phone': ..., 'left': ..., 'right': ...}.
Вставка и поиск итеративные (циклы), удаление рекурсивное с поиском inorder‑преемника.
Операции везде: insert, find, delete, list_all (для дерева – обход по порядку, для остальных – собрать всё в список и отсортировать).
Эксперимент
Взял 1000 записей вида User_00001 … User_01000.
Подготовил два набора: случайный порядок и отсортированный по имени.
Для каждой структуры и каждого набора:
- Замерял время вставки всех 1000 записей (через
time.perf_counter()). - Затем поиск 110 имён (100 реальных + 10 вымышленных).
- Потом удаление 50 случайных записей.
Каждый замер повторял 5 раз, брал среднее.
Результаты сохранил в results.csv, потом построил график performance.png.
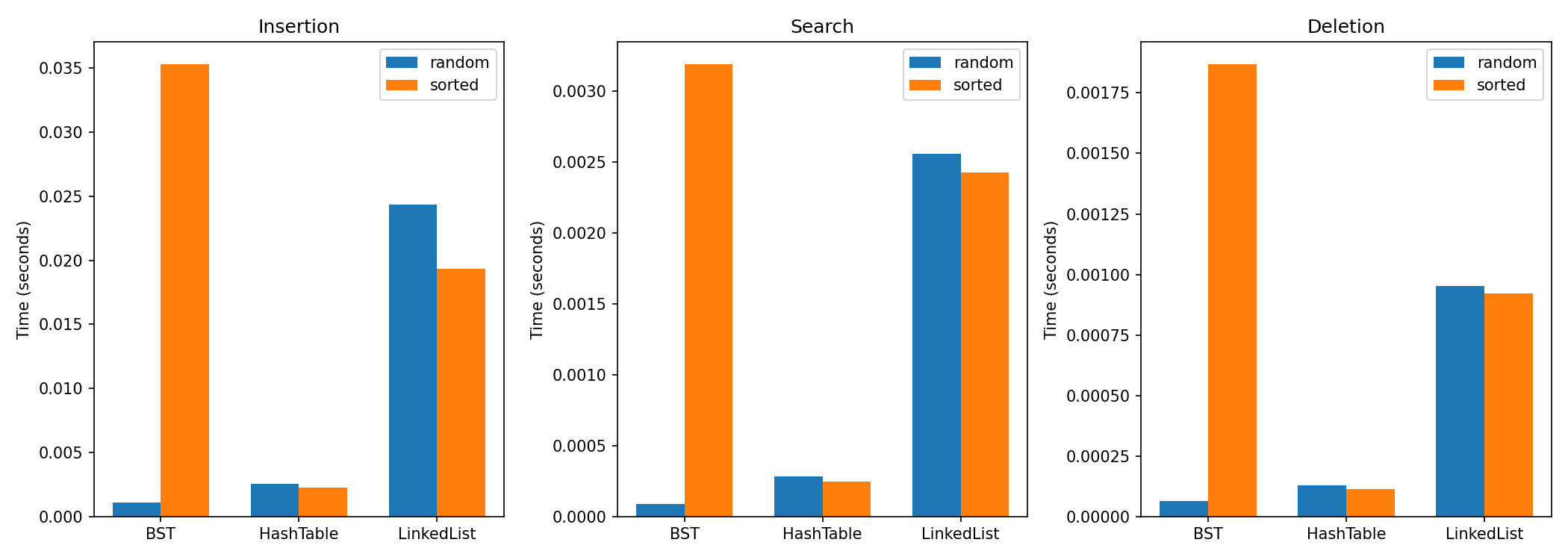
Что получилось (график)
Анализ
BST
На случайных данных работал очень быстро (логарифм). А на отсортированных – ужасно: дерево выродилось в правую цепочку, высота стала 1000. Вставка замедлилась в ~58 раз, поиск и удаление тоже сильно просели. Это классическая проблема небалансированного дерева.
Хеш-таблица
Порядок данных почти не влияет. И в случайном, и в отсортированном режимах время одинаковое. Хеш-функция разбрасывает записи по корзинам, поэтому ей всё равно, откуда приходят данные.
Связный список
Ожидаемо медленный везде, потому что поиск всегда линейный (O(n)). Разницы между случайным и отсортированным нет – список не умеет использовать порядок.
Удаление – похоже на поиск по скорости, плюс чуть-чуть на перестановку ссылок. У хеш-таблицы удаление быстрее всего.
Выводы
- Хеш-таблица – лучший выбор, если нужен быстрый поиск и порядок вывода не важен. Стабильна и проста.
- Двоичное дерево поиска – хороший вариант, если часто нужен отсортированный список, но только при случайных данных. Если данные могут прийти отсортированными, дерево сломается (станет как список). Надо брать сбалансированное (AVL, красно-чёрное).
- Связный список – для реальной базы контактов не годится. Можно использовать только когда записей совсем мало (до сотни) или чисто в учебных целях.
Для телефонного справочника с тысячами записей я бы взял хеш-таблицу, а если надо часто выводить по алфавиту – сбалансированное дерево.