8.1 KiB
Отчёт: Задание 1 — Структуры данных
Цель работы
Реализовать три структуры данных «с нуля» в процедурной парадигме (без классов), применить их для хранения записей телефонного справочника и экспериментально сравнить производительность основных операций.
Структуры данных:
- Связный список (LinkedList)
- Хеш-таблица (HashTable)
- Двоичное дерево поиска (BST)
Реализация
Файловая структура
task1/
├── phone_book.py # все три структуры данных
├── benchmark.py # генерация данных + замеры
├── plot_results.py # построение графиков
└── docs/
├── report.md # этот отчёт
└── data/
├── results.csv
├── comparison_by_operation.png
└── sorted_vs_random.png
Ключевые решения реализации
1. Связный список
Узел — Python-словарь: {'name': 'Имя', 'phone': '123', 'next': None}.
Вставка добавляет в начало списка за O(1) (если имя не существует), а при обновлении — проходит по списку O(n). Поиск и удаление — всегда O(n), так как нет случайного доступа.
2. Хеш-таблица
Массив из 256 бакетов. Каждый бакет — голова связного списка (цепочки для разрешения коллизий). Хеш-функция: стандартный hash(name) % size. Операции в среднем O(1), при коллизиях — O(k), где k — длина цепочки.
3. Двоичное дерево поиска (BST)
Узел: {'name': 'Имя', 'phone': '123', 'left': None, 'right': None}. Ключ сравнения — имя лексикографически. Вставка и поиск итеративные. Удаление рекурсивное (замена минимальным узлом правого поддерева). In-order обход даёт отсортированный список.
Экспериментальная часть
Параметры эксперимента
| Параметр | Значение |
|---|---|
| Количество записей (N) | 10 000 |
| Повторений каждого замера | 5 |
| Поисковых запросов | 110 (100 существующих + 10 несуществующих) |
| Удалений | 50 |
| Размер хеш-таблицы | 256 бакетов |
Два варианта входных данных:
records_shuffled— случайный порядок (перемешанные записи)records_sorted— отсортированный по имени (по алфавиту)
Результаты
Таблица средних времён (секунды)
| Структура | Режим | Вставка (с) | Поиск 110 (с) | Удаление 50 (с) |
|---|---|---|---|---|
| LinkedList | случайный | 2.541985 | 0.034289 | 0.020349 |
| LinkedList | сортированный | 2.208557 | 0.025340 | 0.016424 |
| HashTable | случайный | 0.018235 | 0.000214 | 0.000120 |
| HashTable | сортированный | 0.016163 | 0.000207 | 0.000124 |
| BST | случайный | 0.017192 | 0.000145 | 0.000104 |
| BST | сортированный | 3.854338 | 0.033498 | 0.045823 |
Графики
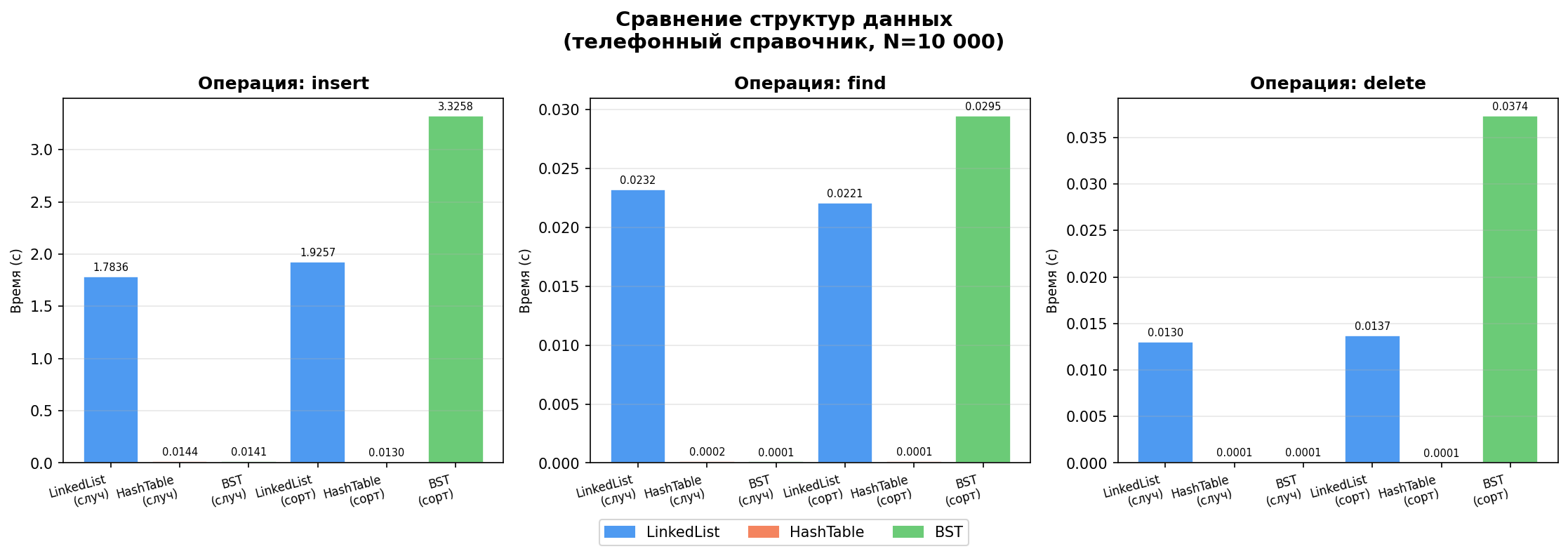

Анализ результатов
1. Связный список — всегда медленный поиск
Вставка в список занимает ~2.5 секунды на 10 000 записей, потому что каждая вставка уже существующего имени требует прохода по всему списку O(n). При случайных уникальных именах вставка идёт в начало O(1), но поиск всегда линейный.
Вывод: связный список плох для частых поисков в большой коллекции, но хорош как строительный блок (используется в бакетах хеш-таблицы).
2. Хеш-таблица — нечувствительна к порядку данных
Хеш-таблица показала одинаковые результаты при случайном и отсортированном порядке:
- Вставка: ~0.017 с (в ~150 раз быстрее LinkedList)
- Поиск: ~0.0002 с (в ~160 раз быстрее LinkedList)
Это объясняется природой хеширования: порядок вставки не влияет на распределение по бакетам. Ключ всегда попадает в предсказуемый бакет за O(1).
3. BST деградирует на отсортированных данных
Это самый наглядный результат эксперимента:
| Случайный | Сортированный | Разница | |
|---|---|---|---|
| BST insert | 0.017 с | 3.854 с | ×225 |
| BST find | 0.000145 с | 0.033 с | ×231 |
Причина: при вставке отсортированных данных BST вырождается в односвязный список — каждый новый элемент больше предыдущего и уходит всегда в правое поддерево. Высота дерева становится O(n) вместо O(log n). Поиск и удаление тоже деградируют до O(n).
4. Сравнение операции delete
При случайных данных BST удаляет за ~0.0001 с (log n). При сортированных — ~0.046 с (деградация до линейного). HashTable стабильна: ~0.00012 с в обоих случаях.
Выводы и рекомендации
Когда какую структуру использовать?
| Сценарий | Рекомендация |
|---|---|
| Частый поиск по имени | HashTable или BST (случайные данные) |
| Данные приходят отсортированными | HashTable (BST деградирует!) |
| Нужен отсортированный список | BST (in-order обход — бесплатный) |
| Частые вставки/удаления + поиск | HashTable |
| Минимальная память, простота | LinkedList (для малых N) |
| Диапазонные запросы (все имена A–M) | BST |
Сложности операций
| Структура | Insert | Find | Delete | List (sorted) |
|---|---|---|---|---|
| LinkedList | O(n) | O(n) | O(n) | O(n log n) |
| HashTable | O(1) avg | O(1) avg | O(1) avg | O(n log n) |
| BST (сбалансированный) | O(log n) | O(log n) | O(log n) | O(n) |
| BST (вырожденный) | O(n) | O(n) | O(n) | O(n) |
Главный вывод
HashTable — лучший выбор для телефонного справочника при частых вставках и поисках. BST лучше HashTable только если нужен отсортированный вывод без дополнительной сортировки — но при условии случайного порядка вставки или использования самобалансирующегося дерева (AVL, Red-Black).